Making Data Center Operations Transparent
CloudSino is dedicated to helping enterprises monitor hardware devices, asset configurations, room environments, energy consumption and capacity, IT resources, O&M processes, and business services comprehensively, reducing O&M blind spots, and improving fault detection, risk warning, and business assurance capabilities.
Data Center Problems: Not the Lack of Tools, but Incomplete Visibility
'%3e%3crect%20id='矩形_10'%20data-name='矩形%2010'%20width='120'%20height='120'%20transform='translate(1425%20-315)'%20fill='none'/%3e%3cg%20id='运维_2_'%20data-name='运维%20(2)'%20transform='translate(1392.319%20-423.829)'%3e%3cpath%20id='路径_1'%20data-name='路径%201'%20d='M211.063,475.288H126.638v23.331h-1.362a5.468,5.468,0,0,1-5.447-5.49V473.915a5.468,5.468,0,0,1,5.447-5.49h87.148a5.468,5.468,0,0,1,5.447,5.49v19.214a5.468,5.468,0,0,1-5.447,5.49h-1.362V475.288Z'%20transform='translate(-76.17%20-305.2)'%20fill='%233becc4'/%3e%3cpath%20id='路径_2'%20data-name='路径%202'%20d='M147.226,664.511a5.472,5.472,0,0,1,5.455,5.49v19.214a5.472,5.472,0,0,1-5.455,5.49H128.135a5.472,5.472,0,0,1-5.455-5.49V670a5.472,5.472,0,0,1,5.455-5.49h19.091Zm-1.364,6.862H129.5v16.469h16.364V671.373Zm-88.636-6.862A5.472,5.472,0,0,1,62.681,670v19.214a5.472,5.472,0,0,1-5.455,5.49H38.135a5.472,5.472,0,0,1-5.455-5.49V670a5.472,5.472,0,0,1,5.455-5.49H57.226Zm-1.364,6.862H39.5v16.469H55.863V671.373Z'%20transform='translate(0%20-476.874)'%20fill='%233ea5ff'/%3e%3cpath%20id='路径_3'%20data-name='路径%203'%20d='M479.319,348.6h6.862v45.29h-6.862Z'%20transform='translate(-390.751%20-200.384)'%20fill='%233becc4'/%3e%3cpath%20id='路径_4'%20data-name='路径%204'%20d='M367.981,119.83a5.467,5.467,0,0,1,5.49,5.444V144.33a5.467,5.467,0,0,1-5.49,5.444H332.3a5.467,5.467,0,0,1-5.49-5.444V125.274a5.467,5.467,0,0,1,5.49-5.444h35.683Zm-1.372,6.806H333.671v16.333h32.938V126.635Zm-6.862,61.25a5.467,5.467,0,0,1,5.49,5.444v19.056a5.467,5.467,0,0,1-5.49,5.444H340.533a5.467,5.467,0,0,1-5.49-5.444V193.329a5.467,5.467,0,0,1,5.49-5.444h19.214Zm-1.372,6.806H341.905v16.333h16.469V194.691Z'%20transform='translate(-257.459)'%20fill='%233ea5ff'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Common O&M Pain Points in Enterprise Data Centers
Hardware Monitoring Blind Spots
The status of servers, storage, networks, security devices, fiber optic switches, and environmental monitoring equipment cannot be uniformly monitored
Inaccurate Asset Data
Reliance on manual entry and periodic inventory, device configurations, component information, maintenance status, and location data are prone to distortion
Low Inspection Efficiency
Limited manual inspection frequency, delayed fault detection, difficult to support large-scale, multi-site data center management
Slow Fault Localization
Scattered alerts and fragmented systems make it difficult to quickly determine which layer the problem occurs in
Insufficient Remote Maintenance Capability
Remote machine rooms, hosted IDC, and unattended machine rooms rely on on-site personnel, with operation processes lacking traceability
Invisible Machine Room Energy and Capacity
Lack of data support for equipment power consumption, cabinet load, temperature hotspots, and U-space availability
IT Process and Resource Data Fragmentation
Events, problems, changes, requests, CMDB, and automated operations cannot form a closed loop
Increasing AI Computing Center Management Complexity
GPU servers, high-density cabinets, liquid cooling, computing resources, and multi-site IDC resources require new management approaches
Starting from Hardware Blind Spots to Complete the O&M Foundation
Many enterprises already have application monitoring, network monitoring, log platforms, and work order systems, but there are still obvious blind spots in underlying hardware devices.
Server power supply, fans, disks, array cards, memory CPU、GPU、BMC、 The firmware version, storage controller, fiber switch ports, and dynamic ring device status often cannot be fully, real-time, and uniformly collected.
Once hardware failures are not detected in advance, they may evolve from a component problem to a business interruption. Especially in finance, healthcare, telecom, government/enterprise, and AI computing center scenarios, hardware layer visibility directly affects business continuity.
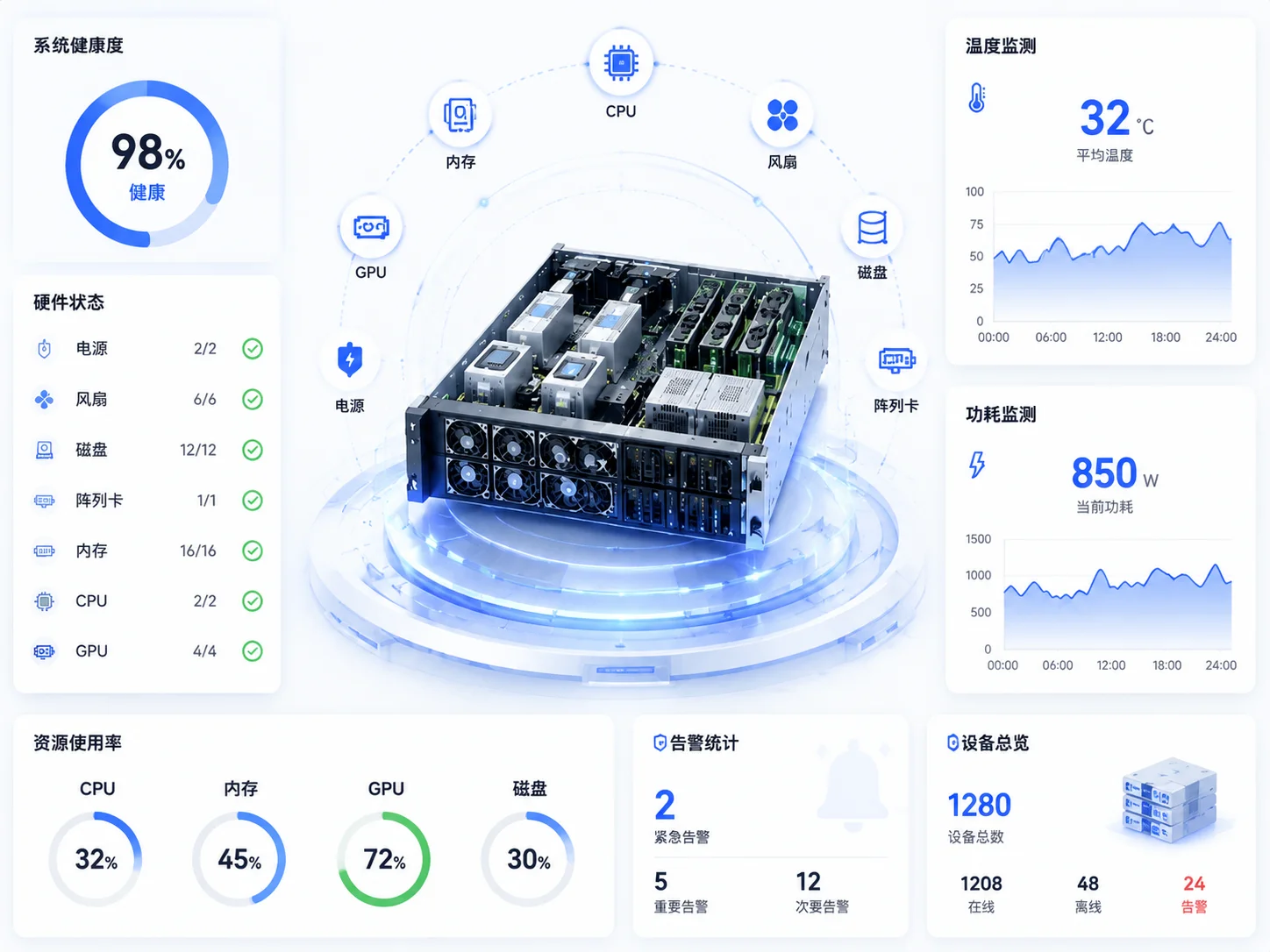
Transforming Asset Data from Manual Ledgers to Real-time Data
Asset management is not simply registering device names and numbers. Truly valuable asset data needs to cover device models, serial numbers, CPU, memory, disks, network cards, GPU, firmware versions, maintenance status, machine room location, cabinet position, U-space information, and configuration change records.
Traditional asset ledgers rely on manual maintenance. A common problem is that they are accurate at launch but start to become distorted after running for a period of time. If device disk replacement, expansion, component replacement, location adjustment, firmware upgrades, and maintenance changes cannot be recorded in a timely manner, subsequent audits, inspections, repairs, expansions, and procurement decisions will be affected.

Multi-site Data Centers Need Unified Monitoring and Remote Maintenance
More and more enterprise data centers are no longer concentrated in a single campus. Headquarters machine rooms, branch machine rooms, hosted IDC, remote disaster recovery centers, overseas nodes, and cloud resources jointly support business operations.
When equipment is distributed across multiple locations, on-site inspections, remote maintenance, asset inventory, device rack mounting/unmounting, and fault handling all become more complex. In hosted IDC scenarios, if on-site personnel perform disk replacement, restart, rack mounting, or adjustment operations, the headquarters O&M team also needs to know what happened in a timely manner.

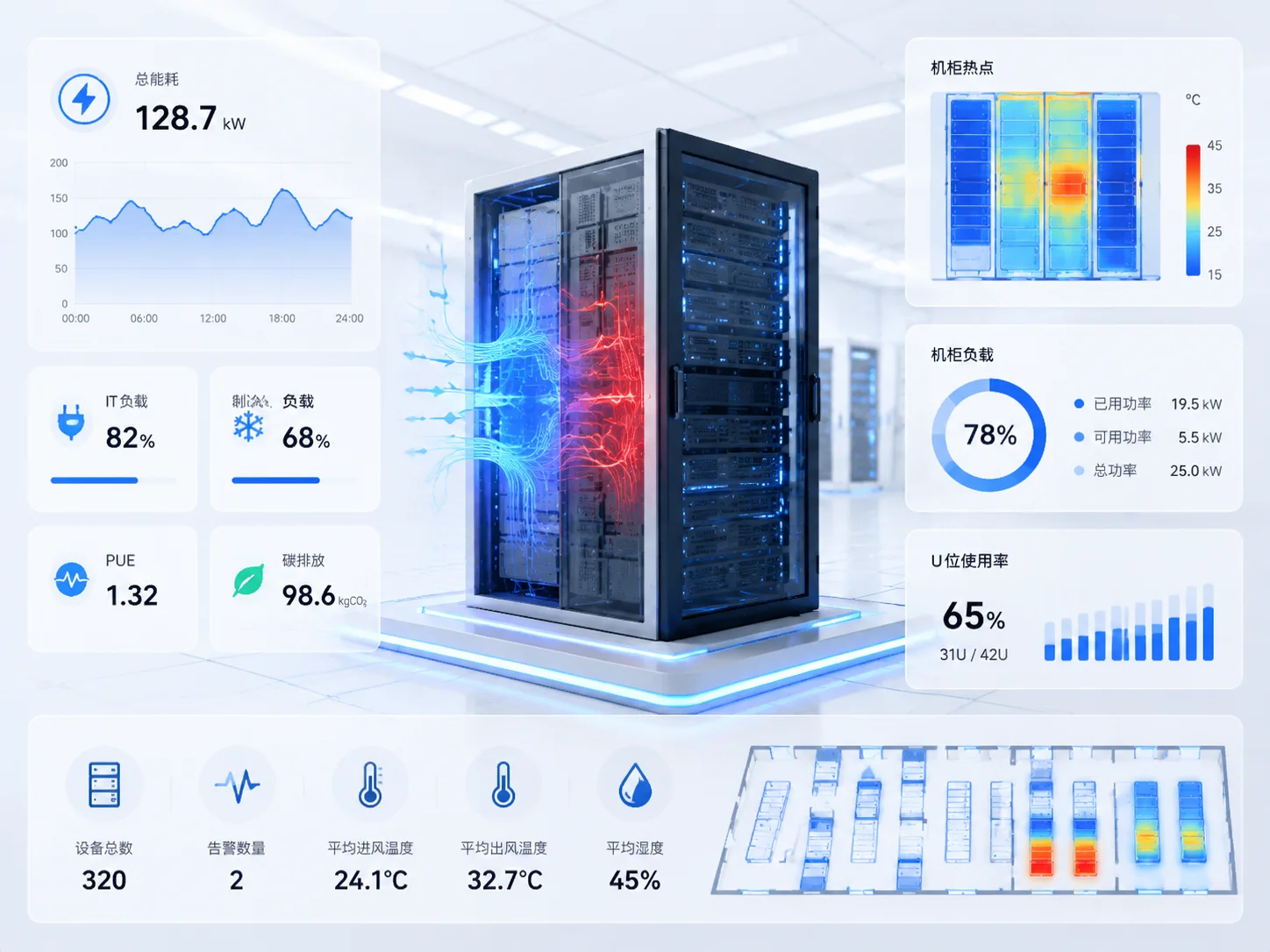
Energy Consumption, Temperature, and Cabinet Capacity Cannot Be Judged by Experience Alone
Power supply, cooling, cabinet capacity, and space utilization in data centers are becoming important cost items in O&M management. Especially in high-density cabinet and AI computing center scenarios, single server power consumption is higher, temperature risks are more prominent, and cabinet rack planning is more complex.
If there is a lack of device-level power consumption, inlet/outlet temperature, cabinet load, U-space usage, and hotspot risk data, the O&M team can only rely on experience. This can easily cause cabinet space waste and may also lead to local overheating, power supply overruns, and business risks.
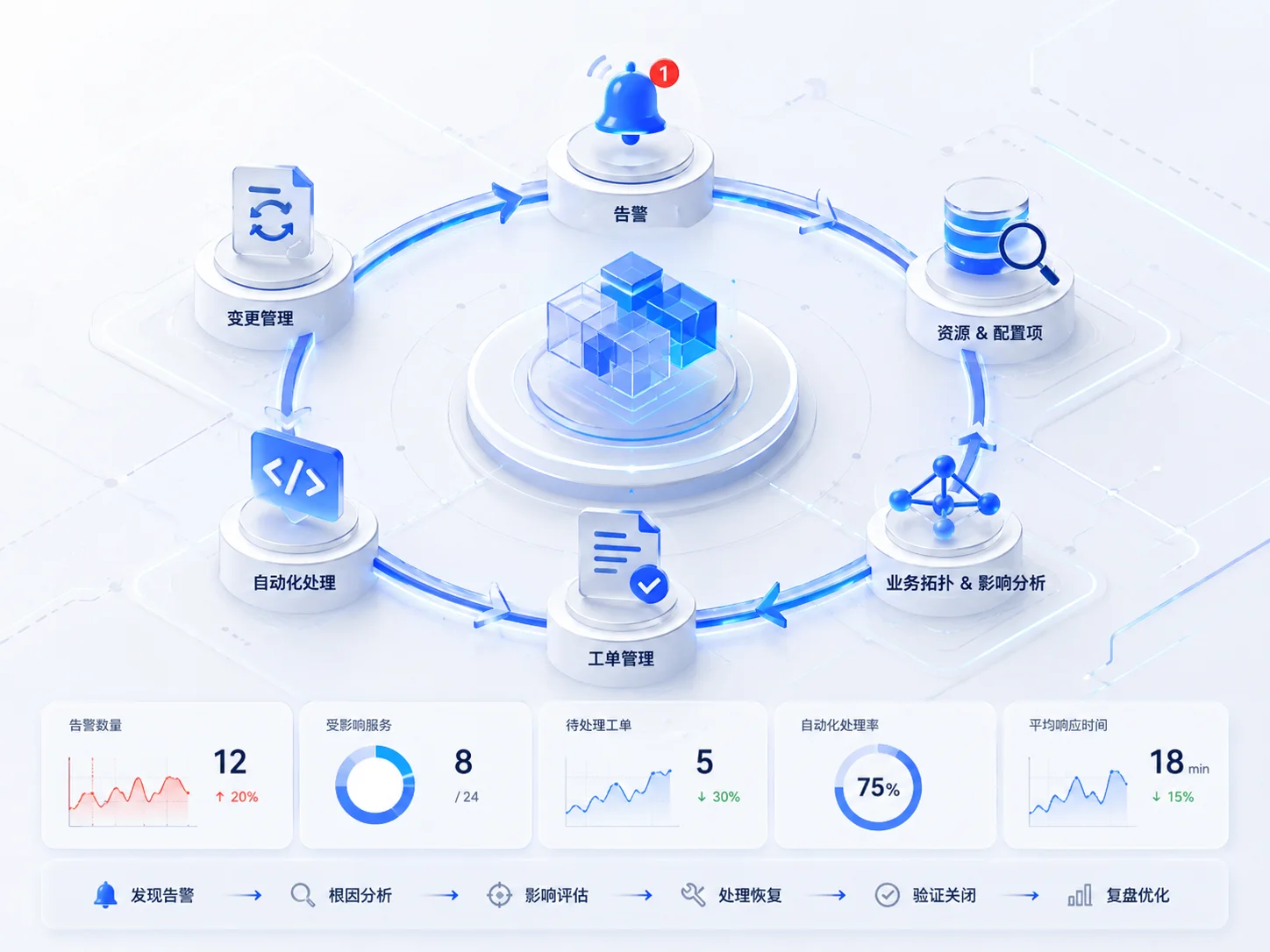
IT Processes, Resources, and Business Services Need to Form a Closed Loop
When a fault occurs, alerts alone cannot solve the problem. Enterprises also need to know which resource the alert comes from, which configuration items are associated, which business services are affected, whether there is already a work order, whether a change is involved, and whether automated processing is possible.
If monitoring, CMDB, ITSM, automation, and business topology are fragmented from each other, the O&M team will switch back and forth between multiple systems, with low processing efficiency, vague responsibility boundaries, and difficulty in post-mortem analysis.
AI Computing Centers Bring New O&M Challenges
AI computing centers are not just about more servers. They bring new challenges such as GPUs, AI accelerator cards, high-speed networks, high-performance storage, high-power cabinets, liquid cooling systems, and multi-site computing resource scheduling.
Traditional data center O&M methods are difficult to fully cover these new types of resources. Enterprises not only need to know whether equipment is functioning normally, but also where GPU resources are located, how utilization is, whether energy consumption is abnormal, whether cabinets can continue to be loaded, whether temperature is approaching risk points, and whether computing power businesses are affected.

Core Scenarios Covered by CloudSino
O&M Scenarios for Key Industries
Finance
Equipment stability, asset auditing, configuration changes, regulatory reporting, and business continuity assurance
Healthcare
Unified management of hospital core systems, multiple virtualization platforms, storage networks, power environment, and AI computing equipment
Government & Public Sector
State-owned asset management, Xinchuang infrastructure monitoring, asset inventory, and unified O&M
Telecommunications
Large-scale equipment monitoring, centralized out-of-band management, dedicated line status monitoring, and remote batch control
Manufacturing & Energy
Multi-vendor equipment unified monitoring, critical business system assurance, network links, and data center energy optimization
Education & Research
Campus data centers, research computing platforms, unified asset management, and automated inspection
AI Computing Center
GPU servers, AI computing resources, high-density cabinets, power/cooling systems, and multi-site IDC O&M
Transportation
Ensuring core business continuity of toll systems, monitoring systems, and communication systems, with unified management of geographically distributed devices
What Enterprises Can Gain
CloudSino does not just solve a single point-tool problem, but helps enterprises connect key objects in data center O&M.
Earlier Detection
Enterprises can detect hardware failures and environmental risks earlier
More Accurate
More accurately grasp asset and configuration changes
More Efficient
More efficiently handle events, problems, and changes
Clearer
More clearly determine the impact of infrastructure anomalies on business services
First See the Problems Clearly, Then Build a Unified O&M System
If your data center is facing hardware monitoring blind spots, inaccurate asset data, difficulty managing multi-site machine rooms, invisible energy consumption and capacity, difficult alert localization, or rapid expansion of AI computing resources, CloudSino can help you review the current situation and design a suitable intelligent O&M solution.